由于PC后台管理系统之前由一名工程师独立开发,因此项目文档几乎为0。随着用户数量的不断增加,DB层的压力也越来越大,用户数量也即将突破500万,预计到了年底用户数量会到达千万级,分库分表势在必行
但分库分表的前提是先把业务理清楚,由于文档的缺失,很多业务逻辑就连项目的开发者本身都忘记了,因此重新梳理业务逻辑的第一步,就是引入一个好用的API管理工具
没有最好的,只有最合适的
纵观目前市面上的API管理工具,最终遴选出:Knife4j、Apizza、YApi,这三者各有优劣,这里简单分析一下
| Knife4j | Apizza | YApi | |
|---|---|---|---|
| 是否收费 | ❌ | 小型团队(2人或以下)免费(功能受限),更大型的团队需要收费(功能完整) | ❌ |
| 是否开源 | ✔ | 阉割版是开源的,收费的版本闭源 | ✔ |
| 实现原理 | 在swagger基础上,提供了定制的web页面,更符合国人习惯 | Apizza是一个独立的项目,专门用于API的管理,官方提供有偿的私有部署的服务 | YApi是一个独立的项目,可单独部署在远程服务器,专门用于API的管理 |
| 文档地址 | knife4j (xiaominfo.com) | Apizza 帮助中心 (teambition.com) | YApi-教程 (baidu.com) |
上述表格是一个简单的横向对比,我们再来详细看看它们的优劣
Knife4j
在很早之前它其实不叫Knife4j,叫做swagger-bootstrap-ui,顾名思义,其实就是将swagger原生的页面进行了替换,更符合国人的阅读习惯
优势
随着Knife4j作者不断的更新迭代,Knife4j也越来越强大,不仅仅是基于swagger,它还在swagger的基础上做了一系列的增强,包括但不限于:
i18n国际化:接口文档支持中英文
访问页面加权控制:外部人员不知道用户名和密码,无法查看接口文档的web页面
生产环境屏蔽资源:生产环境屏蔽所有swagger相关资源
API全局搜索
支持接口mock
易于维护:凡是跟API文档有关的工作,维护必然是关键性的。假设我们有很多的API请求参数都用到了实体A,但梳理业务之后,我们发现实体A中的n个属性是没有必要传入的,将实体A中无用的n个属性删掉即可,接口文档会自动更新,不需要再去一个个的手动维护
等等一系列增强功能,作为一款不收费的开源软件,我觉得它的功能还是很强大的
劣势
- 侵入性强:Knife4j底层最终还是依赖的是swagger,它基于注解,因此对于我们接口本身具有很强的侵入性,如果我们想要预先生成请求报文,需要在请求报文对应的实体类上加入对应的注解,因此对实体类本身也有侵入
YApi
YApi是去哪儿的研发团队做出来的一款API管理工具,它跟swagger没有任何关系,因此它不会对我们的API造成入侵,而且它的权限做的比较到位,便于团队管理。和Knife4j相比,它更加重量级,因为它已经是一个单独的项目了,专门用于管理API
优势
- 完善的权限管理
- 支持内网部署,部署流程简单
- 代码侵入性为0
- 支持高级mock
劣势
- 项目较重:体量相比于knife4j更重,由于是一个独立的项目,需要专门部署在内网中
- 学习成本略高:由于是一个单独的项目,且完成度很高,因此开发人员需要付出一定的时间去学习和适应
- 不易维护:假设我们有很多的API请求参数都用到了实体A,但梳理业务之后,我们发现实体A中的n个属性是没有必要传入的,将实体A中无用的n个属性删掉还不够,我们还需要去手动的修改YApi中涉及到实体A的API的请求报文
Apizza
整体风格仿照Postman实现,易于上手,并且在生成接口文档方面进行了优化,可以在文档之间复用公共资源。一处定义,全局使用,同步更新,缺点是收费
优势
整体风格仿照Postman,学习成本低
文档之间复用公共资源
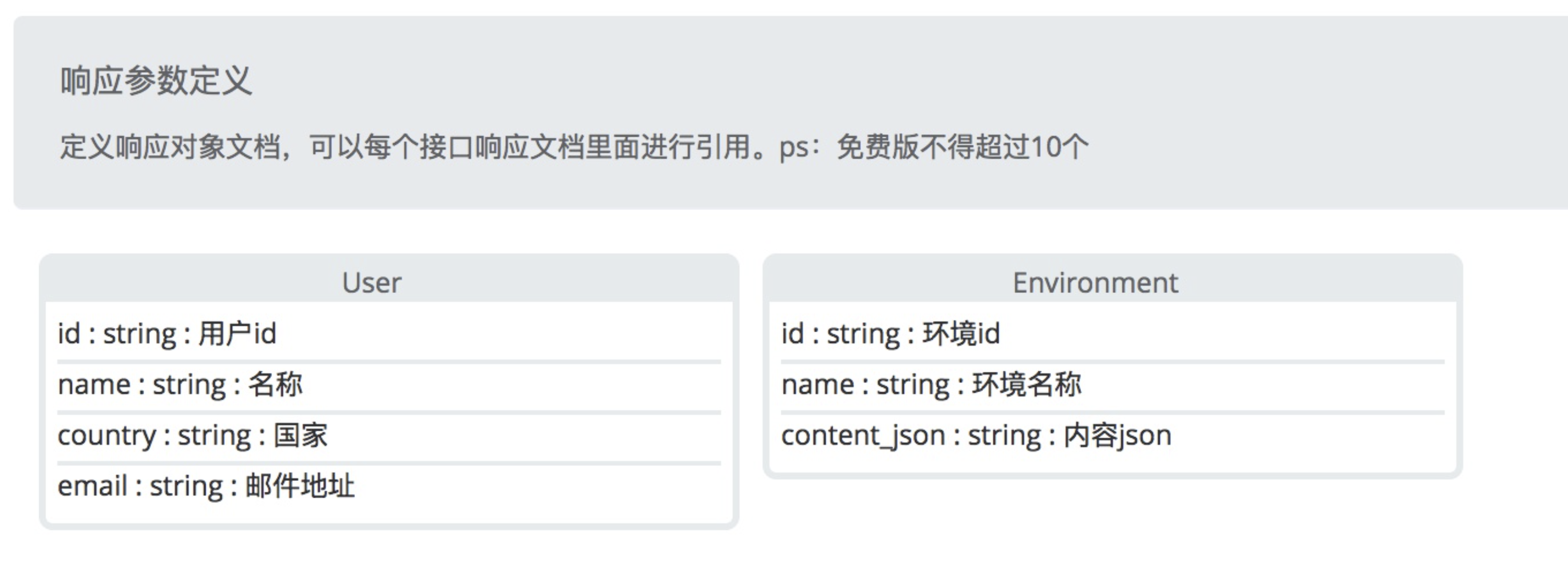

假设我们有很多的API请求参数都用到了实体A,但梳理业务之后,我们发现实体A中的n个属性是没有必要传入的,将实体A中无用的n个属性删掉之后,再更新下Apizza中的模型A的定义就可以了,不需要再去修改一个个的API文档(前提是你的报文已经绑定了模型A)
劣势
收费